Designing an AI Triage Assistant Without Letting AI Make Clinical Decisions
2026-05-06
If you’ve seen The Pitt, you know how hectic a hospital floor can be. What the show does not fully capture is the number of alerts clinical staff receive over the course of a shift.
A bedside nurse may see telemetry alerts, oxygen saturation warnings, infusion pump alarms, fall-risk notifications, and nurse call escalations all while managing patients, family questions, documentation, and the thousand small things that keep a unit running.
The problem is not that alerts are useless. The problem is that too many alerts arrive with too little context. One system may say something is urgent without explaining why. Another alert may look routine, but actually be part of a worsening pattern. Over time, that volume creates alert fatigue. Staff become overwhelmed, and truly important signals can become harder to spot.
That was the starting point for my project: Clinical Alert Triage Assistant, a simulated clinical alert triage system built around one core constraint:
The AI should help explain alerts, not make clinical decisions.
That constraint came from conversations I’ve had with nurses and clinical staff during healthcare technology implementations. In clinical environments, systems need to earn trust. If they feel opaque, noisy, or disconnected from real workflows, they risk being ignored.
Try the live demo
Interact with the triage assistant — submit simulated alerts and see the AI explanation layer in action.
The Product Problem
The goal was not to build a doctor in a box. That would be a terrible idea, and probably a very stressful box.
The goal was to explore a narrower and more realistic question:
Can AI help make clinical alerts easier to understand while keeping deterministic rules and human review in control?
For this MVP, I focused on six simulated alert types:
- telemetry tachycardia
- low oxygen saturation
- infusion pump alarm
- nurse call escalation
- fall-risk alert
- sepsis screening
Each alert needed to produce a clear triage output:
- baseline severity from rules
- final priority
- destination or response team
- structured explanation
- confidence level
- rules vs. AI indicator
- audit log entry
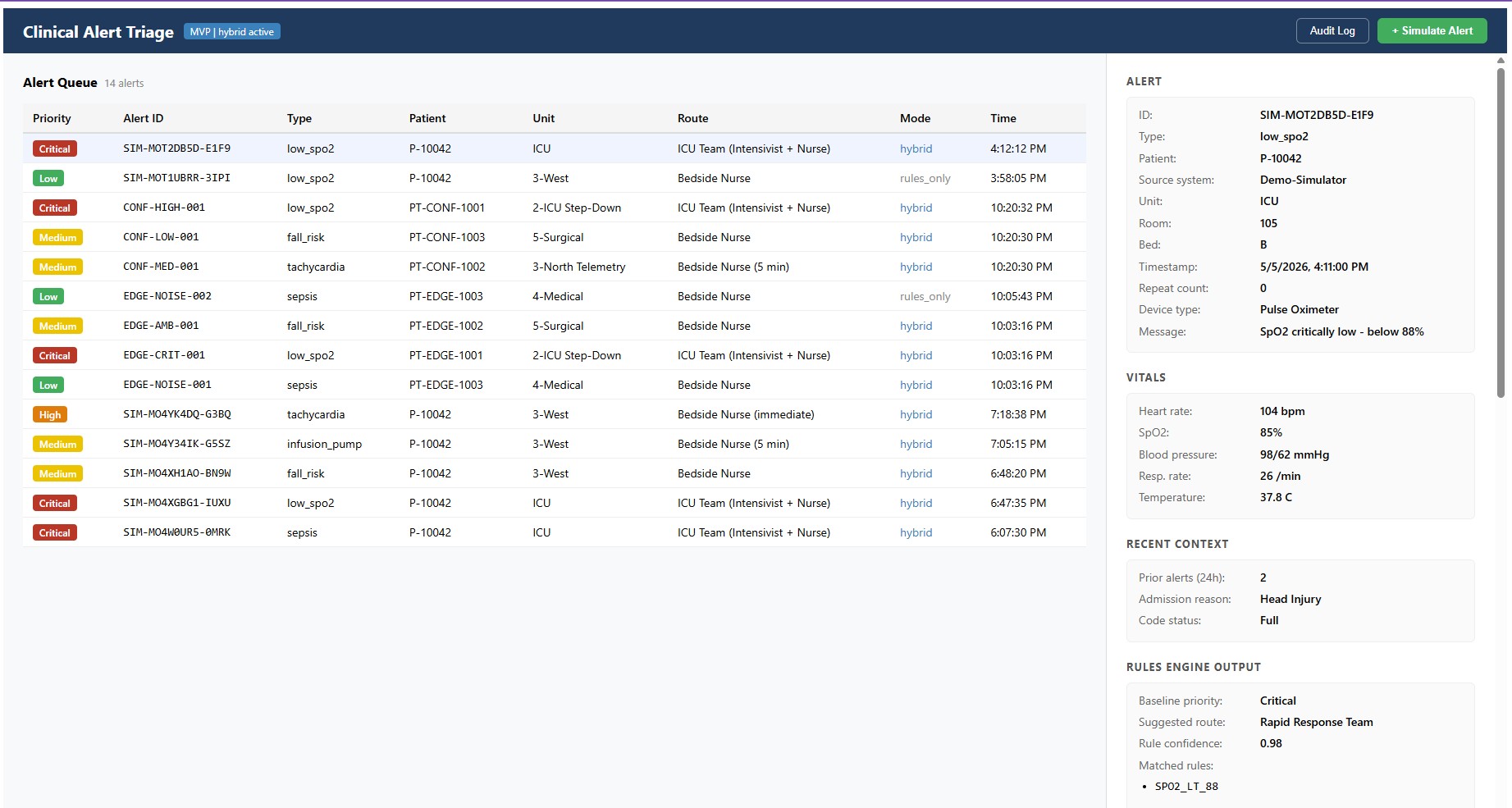
The system was designed as decision support, not autonomous decision-making. That may sound like a small distinction, but it shaped almost every design decision that followed.
The Key Design Decision
The most important decision was separating authority from explanation.
In this system:
- The rules engine defines the minimum severity.
- The LLM writes a structured explanation.
- The decision layer enforces guardrails.
- The human accepts, overrides, or gives feedback.
- The audit log records what happened.
The LLM does not get to quietly become the decision-maker.
If a rule says an alert is critical, the LLM cannot downgrade it. If the model output is malformed, missing, or low confidence, the system falls back to rules-only mode. If a human overrides the result, the original system decision is still preserved for review.
That became the operating principle for the project:
Rules are the safety floor. AI is the communication layer. Humans stay in control.
Why Scope Control Mattered
It would have been easy to chase realism too early.
Real hospital integrations would have made the demo feel more authentic. Streaming alert pipelines would have been interesting. EHR data would have added depth.
But all of that would have pulled the project away from the core question.
Instead, I chose simulated JSON alerts and a focused workflow. That kept the project centered on the behavior I wanted to test:
- Can the system classify alerts consistently?
- Can it explain why an alert was prioritized?
- Can it show uncertainty clearly?
- Can a human review or override the result?
- Can every action be audited?
In a real clinical environment, integrations, data feeds, identity management, security, and validation would all matter. For this MVP, the better choice was to prove the core workflow before adding operational complexity.
The Users I Designed Around
I framed the system around three user groups.
Bedside nurses need quick, readable explanations. They do not need a wall of technical reasoning while managing an active shift.
Charge nurses and rapid response teams need clear escalation signals and routing rationale.
Clinical informatics and QA teams need auditability. They need to know what the system saw, what rules fired, what the AI generated, and how humans responded. They also need the ability to adjust the model responses by providing feedback and cues to the LLM.
Thinking through those users was a helpful exercise that pushed the project away from being a backend-only demo. The explanation panel, override flow, feedback capture, and audit log all came from asking who would actually need to trust, use, or review the system.
What the System Does
At a high level, the workflow looks like this:
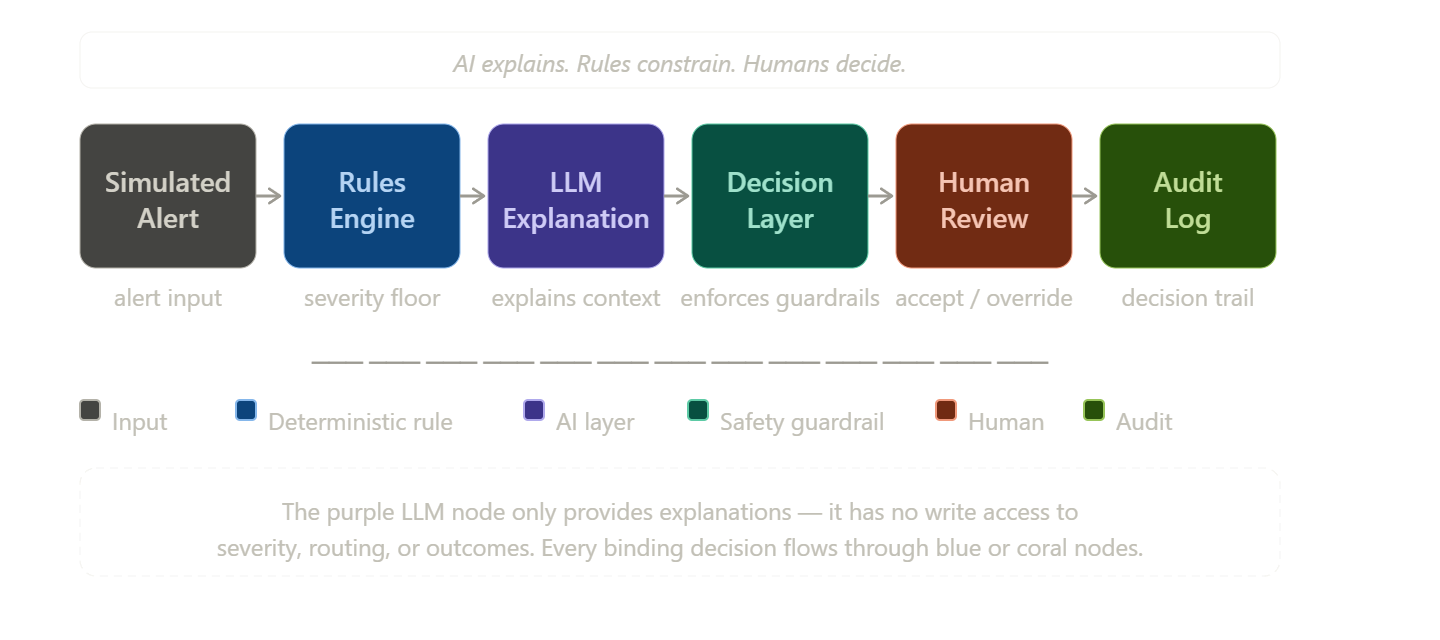
For example, if an oxygen saturation alert crosses a critical threshold, the rules engine sets the severity floor. The LLM can help explain the contributing factors and uncertainty, but it cannot make the alert less urgent.
That type of constraint makes the AI feature more credible, not less.
| System Component | Role in the Workflow | Explicit Boundary |
|---|---|---|
| Rules Engine | Sets the severity floor using deterministic alert logic and predefined clinical thresholds. | Does not generate natural-language explanations or interpret nuance beyond the rules. |
| LLM Explanation Layer | Turns alert details, rule outputs, and uncertainty into a readable explanation. | Cannot downgrade critical alerts, change rule-based severity, or make clinical decisions. |
| Decision Layer | Enforces guardrails, validates model output, and triggers fallback behavior when needed. | Does not rely on the LLM without checks or allow unsafe outputs to pass through. |
| Human Reviewer | Reviews the alert, accepts or overrides the output, and adds feedback when appropriate. | Does not have to blindly accept the system's recommendation. |
| Audit Log | Preserves the rule output, AI explanation, final priority, human action, and override history. | Does not make recommendations or alter the decision trail after the fact. |
The Explainability Standard
Healthcare professionals are understandably cautious about AI systems that influence patient care. Trust is especially difficult when a model behaves like a black box or produces outputs that cannot be validated against clinical reasoning.
For that reason, I designed the LLM feature around explanation rather than instruction. The goal was not to tell nurses what to do. The goal was to make the system’s reasoning visible enough for a human to evaluate it quickly.
Every explanation needed a consistent structure:
- Summary
- Key factors
- Routing rationale
- Uncertainty
- Rule trace
- Verification guidance
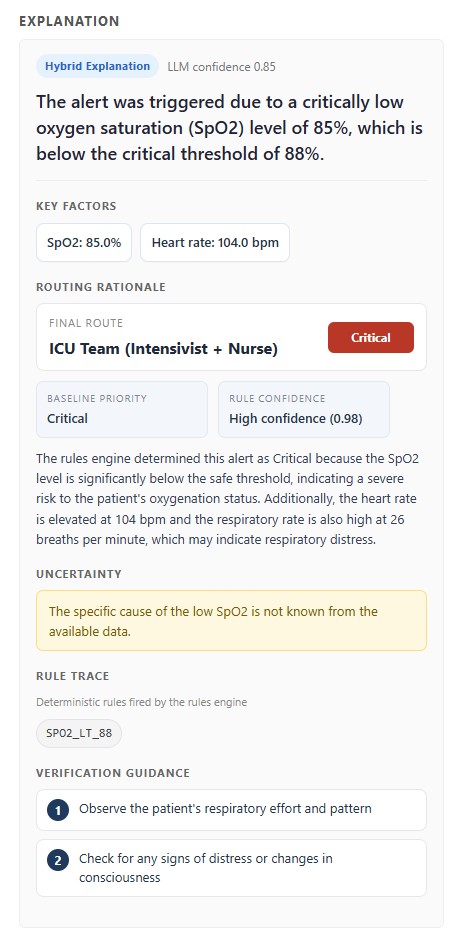
This became one of the biggest lessons from the project.
“Explainability” is vague until you define what a good explanation must contain. A summary alone is not enough. A confidence number alone is not enough. A model-generated paragraph without a rule trace is not enough.
The explanation has to help a human understand:
- what happened
- what evidence mattered
- why the alert was routed a certain way
- what remains uncertain
- which deterministic rules fired
- what should be verified next
That structure made the AI output easier to evaluate and much easier to design around in the UI.
What This Project Shows
This project was less about building a flashy AI wrapper and more about designing a responsible AI workflow for a high-risk environment.
A useful LLM integration does not always mean giving the model more authority. Sometimes the better design is giving it a narrower job and surrounding it with clear rules, fallback behavior, auditability, and human review.
In this case, the model’s job was explanation.
That narrower role made the system easier to reason about. The rules engine handled severity floors. The decision layer enforced boundaries. The UI made uncertainty and rule traces visible. The audit log preserved what happened.
The result was not an autonomous clinical system. It was a prototype for how AI could improve clarity without taking control away from clinicians.
What I Learned
The biggest lesson was that responsible AI design starts before the first API call.
It starts with questions like:
- What should the model be allowed to do?
- What should it never be allowed to do?
- What happens when it is wrong?
- What happens when it is unavailable?
- How will a human know what influenced the output?
- How will decisions be reviewed later?
Those questions shaped the architecture more than the model choice did.
The LLM was useful, but the guardrails, rule trace, fallback behavior, and audit trail are what made the system defensible.
Closing Thought
This project began with a simple idea: clinical alerts should be easier to understand.
The more interesting challenge was figuring out how to use AI without handing it the steering wheel.
That became the core product principle:
Let AI improve clarity. Keep authority with rules and humans.
For safety-sensitive workflows, that is not a limitation. That is the design.